My name is Dmytro, and I am currently an ML Engineer at Levi9 IT Services. I have ten years of experience in data analysis and processing, web services development, and machine learning.
Artificial intelligence helps businesses optimize costs and increase efficiency. This is a relatively expensive technology, but it is worth implementing, especially if you need to process a lot of information. In this article, I propose to deal with the hidden but necessary costs of MLOps and data preparation.
It will be helpful for you if you are planning to add AI to your project or have already tried to improve it in this way but failed.
Working with AI and ML: Pros and cons
The needs and expectations of customers of any modern business are high, and to provide products and services that will satisfy them, it is often necessary to process a lot of data. Due to the interest of global companies in big data and analytical systems, the Data Science market is growing – it is expected to reach almost $323 billion by 2026. Businesses are investing in data and artificial intelligence, so the demand for Data Science specialists is growing.
Still, working with data is not always easy, and a 2022 study aimed at determining the state of play in the Data Science industry will help to understand what exactly can go wrong. A survey of 300 industry professionals, including data analysts, data scientists, ML, and data engineers, showed that they often face the following problems:
- Implementation of AI elements is slow and can take a year instead of the planned two months;
- It is more expensive than expected;
- Low quality of the model;
- It does not fit the technological stack;
- The production data differs significantly or may differ over time.
According to the research, most respondents believe it is challenging to implement AI elements in projects because specific models are already in place, but financial and technical capabilities are limited.
If AI is implemented, it is impossible to fully meet the needs of the business because the model’s efficiency is lower than expected, it requires too many resources to support it, or it does not integrate well with the existing architecture. More details on the problems of AI implementation can be seen in the following graphs.
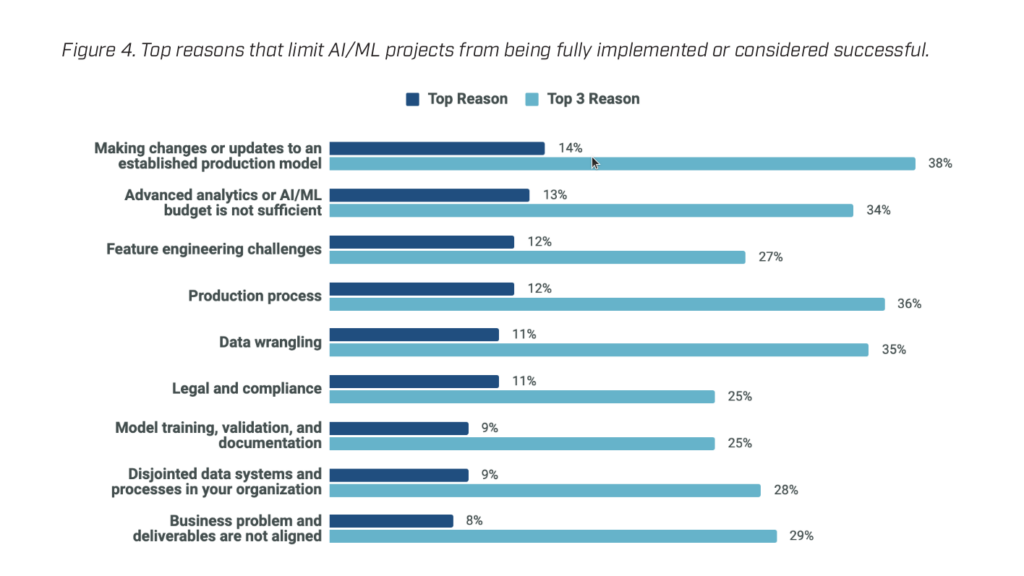
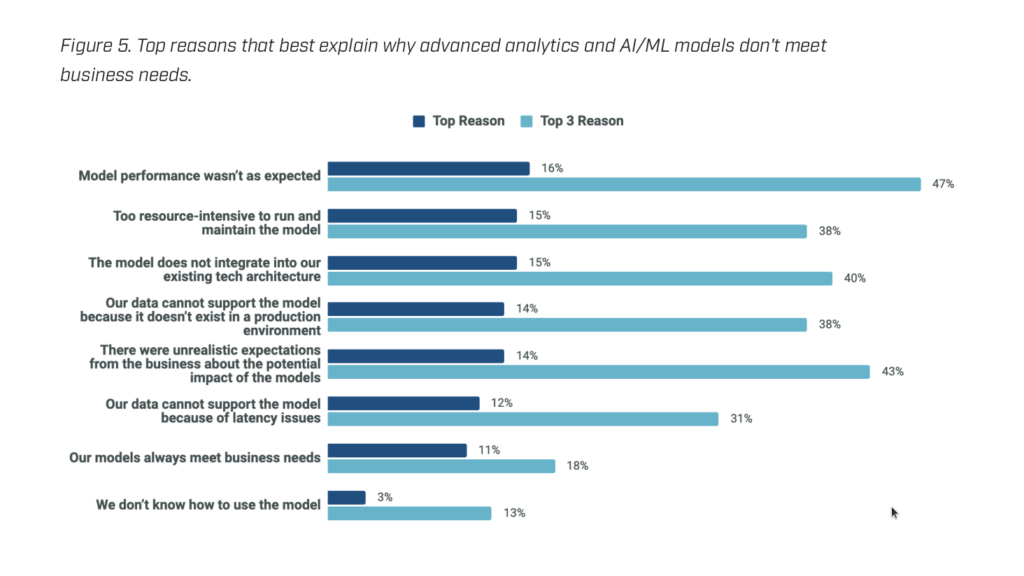
Why are the deadlines higher than expected?
The research aptly notes that everything takes time, and the problem is mainly in incorrect expectations when planning a project. However, technologies based on artificial intelligence require more time for quality development.
Machine learning is a product just like traditional software, and high expectations are also common. Today, it is hard to imagine a smartphone keyboard without auto-complete, an online store without a selection of recommended products, social networks without personalized advertising, etc. Today’s consumers are more demanding and have high expectations, but innovations don’t appear in two days.
Businesses are trying to meet expectations and are often in a hurry. And if there is also a lack of real experience in AI implementation, a “domino effect” occurs, and problems overlap.
Specialists underestimate data collection, processing, and dataset creation, while the key to a successful ML solution is a good set of relevant data. The second underestimated problem is MLOps, mainly due to complex data and model monitoring. This is a rather broad topic that colleagues explained well in this article.
Why is AI implementation more expensive than expected?
The cost of implementing AI-based technologies is linearly related to the timeframe of the task. Paying for the team’s work, computing power, and other services for three months is more profitable than a year.
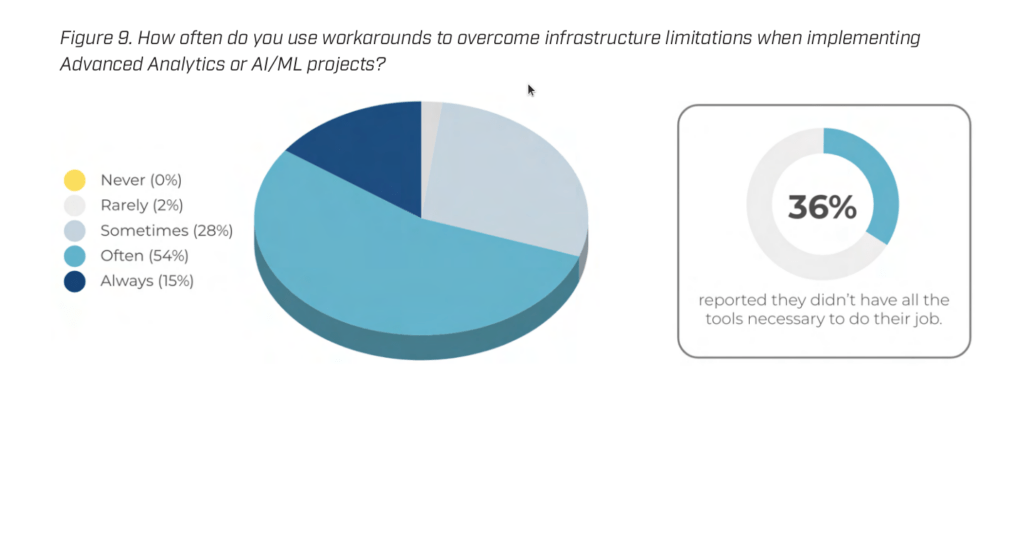
However, there are other factors. For example, cloud providers actively convince you that you will receive a ready-made model by transferring data to their black box. Build, train, and deploy, and there are a lot of examples on the Titanic or MNIST datasets. Everything seems very simple, but in 7 out of 10 cases, the task is more complicated and requires some workarounds.
Why is the quality of the solution lower than expected?
The following indicators usually assess the quality of an analysis or model in ML:
- Business metrics (LTV, CSAT, financial performance, etc.)
- Metrics of "accuracy" of a particular model (F1, precision, recall, [R]MSE, map, dice, etc., depending on the "family")
- Infrastructure metrics (throughput, latency, error rate, RAM/CPU/GPU utilization, device temp, power consumption, etc.)
Instead, the solution may be of poor quality if the target metrics are:
- Unrealistic - and that's okay because such metrics show real affairs. If you need a 98% Recall rate to make your solution profitable, that's fine. The other question is whether to try to achieve it or abandon ML.
- Randomly generated or taken from SOTA is not okay because metrics from other or similar data are irrelevant to your problem and business. Perhaps an 85% Recall is enough for you, but by aiming for 98%, you risk never reaching it and losing a good solution.
- Absent or "as high as possible" is not okay because, without metrics, neither the business nor the specialist understands why they need AI. And if there are no infrastructure metrics, then there may be the following conditional situation: the team performs object detection & tracking on mobile devices. It receives high target accuracy rates from analysts.
They’ve done it, converted it, and implemented it in an app, and suddenly users complain that their phones overheat, freeze, and the battery dies quickly. It turns out that they need to shrink the model or choose a different architecture, but they can’t meet the metrics. As a result, the team has wasted at least six months of work.
Business metrics are directly or indirectly correlated with accuracy metrics – the better they are, the better the business metrics are if they are chosen correctly. And model accuracy metrics and infrastructure metrics are almost always inversely correlated, although it happens that after model pruning, they are better generalized or remain at the same level. It’s always a trade-off, so we must set all kinds of metrics in advance.
Why is the data on the production different?
When the data on the production changes, one of the following situations can happen:
- You've noticed it over time, which is fine.
- You realized this as soon as you deployed the solution, and this is not okay.
Over time, the data distribution changes, and this is normal – you need to react correctly and in time, such as recognizing data drift and re-training models on new data. This is what MLOps tools are for.
If you deploy a solution and immediately see that the model behaves strangely, it’s a bad call. You may have had a data leak, no test set, or the data sample for training was unrepresentative. Data collection and processing in this pipeline are essential.
How to do it right
This scheme illustrates the basic algorithm for implementing AI but is worth elaborating on certain stages.
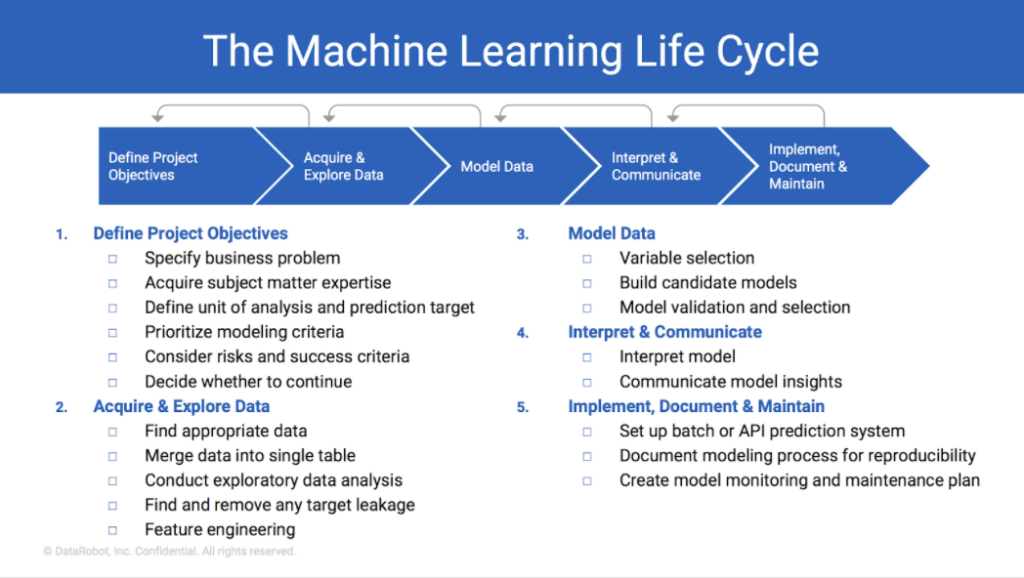
- If you have completed step 1, you start conducting experiments. At this stage, you should have a set of target metrics that you document and communicate to your team or contractor. And it would be best if you considered how much data you have. If you have a lot of data in the cloud, you should immediately work in services like AWS SageMaker and not transfer a bunch of data to your PC.
- If everything is fine, metrics are met, there is no information leakage, and you are ready to deploy the model, take your time. Move all the code from the jupyter-laptops to the repository, untangle it, and make a more or less ordinary code design for training/evaluation/inference (i.e., using the deployed model).
- Make the pre/post-processing code standard, not "copy-paste".
- Create ETL jobs for dataset preparation and augmentations, or in other words, transformations.
- Add data versioning, such as Pachyderm, DVC, or just s3 versioning.
- Consider how you will detect Data/Concept drift and other monitoring routines.
- Think about how you will collect labels for new data (as part of supervised learning). You need new data to retrain models and assess their quality.
In other words, please don’t create a substantial technical debt because it tends to grow on itself. And once you deploy the solution, you’ll need “eyes” and methods to monitor this vast mathematical graph.
Key takeaways
The following takeaways provide essential insights on navigating the complexities of implementing machine learning in business, covering metrics prioritization, deadline transparency, leveraging business knowledge, talent selection, and investment in MLOps.
- Metrics first, then experiments. First, set specific quality metrics that can be measured in terms of money. Set a minimum quality limit for the model to understand whether the goal is generally achievable.
- Don't expect clear deadlines during proof of concept, but demand transparency. This is the most chaotic stage, where data analysts/scientists must perform unprecedented tasks, and the next step often depends on the results of the previous one. Hypotheses are either refuted or confirmed.
- Make the most of business knowledge. If you know from your analytics that customers with children are more likely to buy toys, use this at the monitoring stage. If you can write a set of business rules to classify a customer as a potential customer, then choose this method over AI.
- Give preference to experienced specialists if you have limited resources. The industry is still considered young, but specialists have accumulated some experience. This is important because it allows them to choose a simpler/flexible/better solution. At the same time, young talent should also be given a chance.
- Invest in MLOps. It is essential only after clear metrics and experiments prove their achievability.