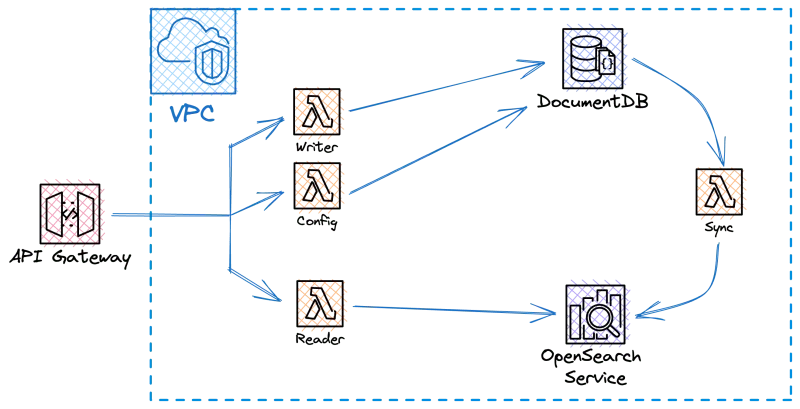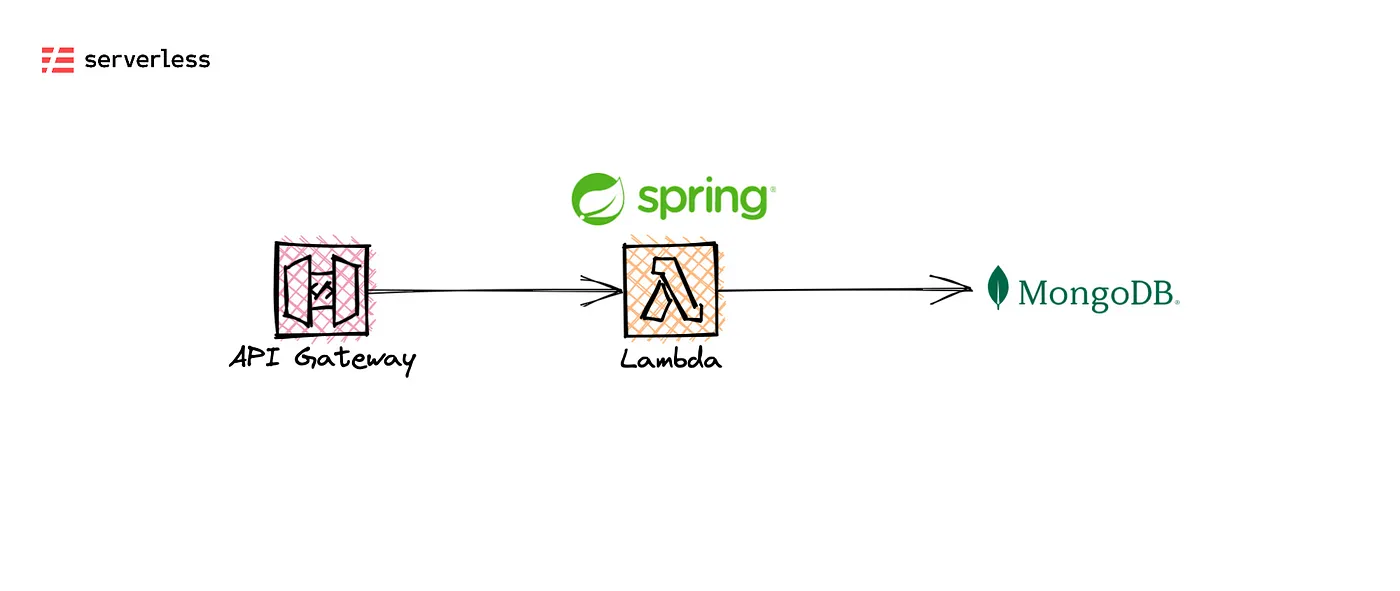
This article will cover how to create an API that returns the closest Starbucks locations near the given point and radius. The API will be backed by MongoDB to utilize geospatial queries, with a Spring Boot app wrapped into a Mono-Lambda on top, deployed seamlessly to AWS with Serverless Framework. When it’s all up in the cloud and working, we will take a closer look at the performance and try to optimize it further by utilizing AWS Lambda SnapStart.
Prerequisites
- Your own AWS account (this exercise fits in the free-tier).
- Serverless Framework installed and configured.
Set up MongoDB Atlas
I signed up for a free MongoDB Atlas account and launched a free cluster in AWS Frankfurt region. To add the test data to the database, I found a collection of US Starbucks locations and forked it to support GeoJSON objects for position. This was needed because I want to index the items in order to be able to perform efficient geospatial queries that Mongo offers. Next, I created a 2dsphere index on the position field. To test if index works, we can execute the following query on MongoDB:
{
position: {
$nearSphere: {
type: "Point",
coordinates: [ -73.9655834, 40.7825547 ] // Central Park
},
$maxDistance: 1000 // 1km
}
}
It should return some results near Central Park. To read more about geospatial queries in MongoDB, feel free to refer to the docs. Now our data is ready, let’s proceed with creating our Spring Boot application that will query Starbucks locations.
NOTE: For the purpose of this exercise make sure that in the MongoDB Atlas Security section, Network Access IP Access List contains the 0.0.0.0/0 rule. That will make the database publicly accessible. None of this is a good idea to do in production, including usage of this free, shared-tier Mongo cluster. More secure way is the use VPC peering, however that is beyond the scope of this article, and it is also not included in the shared-tier MongoDB Atlas cluster.
Spring Boot API
To quickly get up and running with development, let’s use Spring Initializr. After selecting Java 11, Maven, Spring Boot 2.7.8 project properties, and picking Spring Web and Spring Data MongoDB dependencies, we get a project that is ready for further development. Now, let’s create the usual three-layered Repository, Service, Controller setup. We’ll start by creating a StarbucksDocument that represents one MongoDB document:
import org.springframework.data.annotation.Id;
import org.springframework.data.mongodb.core.geo.GeoJsonPoint;
import org.springframework.data.mongodb.core.mapping.Document;
@Document("starbucks")
public class StarbucksDocument {
@Id
private String id;
private String name;
private String address;
private GeoJsonPoint position;
// getters and setters...
}
Leveraging Spring Data MongoDB module, we can create a repository by just extending MongoRepository interface. We get the standard CRUD operations out of the box, so we just need to add a method for querying by position. This way we can fetch stores that are within a given distance from the passed in position, page by page.
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.geo.Distance;
import org.springframework.data.mongodb.core.geo.GeoJsonPoint;
import org.springframework.data.mongodb.repository.MongoRepository;
public interface StarbucksRepository extends MongoRepository<StarbucksDocument, String> {
Page<StarbucksDocument> findByPositionNear(GeoJsonPoint position, Distance distance, Pageable pageable);
}
The repository layer is set up, and we will create a StarbucksService and a StarbucksController so that our API looks like this:
- GET /starbucks/{id}
- GET /starbucks?lng=-73.9655834&lat=40.7825547&distance=2&page=x
If you build and test this, it wouldn’t work of course, because of the missing database connection configuration in the application.properties file:
spring.data.mongodb.uri=mongodb+srv://username:password@clusterxxx.xyz.mongodb.net/dbname?retryWrites=true&w=majority
Make sure to swap the values with the values you obtained from MongoDB Atlas.
🚀 Run it, test it
./mvnw spring-boot:run
curl 'http://localhost:8080/starbucks?lng=-73.9655834&lat=40.7825547&distance=1' | json_pp
{
"data": [
{
"address": "86th & Columbus_540 Columbus Avenue_New York, New York 10024_(212) 496-4139",
"id": "63d52640712420c4e81c9a20",
"latitude": 40.78646447,
"longitude": -73.97215027,
"name": "Starbucks - NY - New York [W] 06186"
},
{
"address": "81st & Columbus_444 Columbus Avenue_New York, New York 10024",
"id": "63d52640712420c4e81c9a26",
"latitude": 40.78335323,
"longitude": -73.97441845,
"name": "Starbucks - NY - New York [W] 06192"
},
{
"address": "87th & Lexington_120 EAST 87TH ST_New York, New York 10128",
"id": "63d52640712420c4e81c9a29",
"latitude": 40.78052553,
"longitude": -73.95603158,
"name": "Starbucks - NY - New York [W] 06195"
},
{
"address": "Lexington & 85th_1261 Lexington Avenue_New York, New York 10026",
"id": "63d52640712420c4e81c9a41",
"latitude": 40.778801,
"longitude": -73.956099,
"name": "Starbucks - NY - New York [W] 06219"
}
],
"total": 4
}
Apparently we have 4 coffee shops within 1 kilometer of Central Park. Nice!
Deploy API to AWS
A few more steps are needed for deploying our API to AWS with the Serverless Framework.
Maven dependency
Add the aws-serverless-java-container-springboot2 dependency to pom.xml:
<dependency>
<groupId>com.amazonaws.serverless</groupId>
<artifactId>aws-serverless-java-container-springboot2</artifactId>
<version>1.9.1</version>
</dependency>
Maven profiles
For convenience, create two Maven profiles — local and shaded-jar . This makes it easier to separate running the app locally and packaging the jar for AWS Lambda. The shaded-jar profile contains the spring-boot-starter-web dependency but without spring-boot-starter-tomcat. To package the app for AWS Lambda, the maven-shade-plugin is used to package all the dependencies into one big jar.
<profiles>
<profile>
<id>local</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</profile>
<profile>
<id>shaded-jar</id>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.2.4</version>
<configuration>
<createDependencyReducedPom>false</createDependencyReducedPom>
</configuration>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<artifactSet>
<excludes>
<exclude>org.apache.tomcat.embed:*</exclude>
</excludes>
</artifactSet>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</profile>
</profiles>
Lambda Handler
Implement RequestStreamHandler for running the app in Lambda. We leverage async initialization described in the aws-serverless-java-container docs.
public class StreamLambdaHandler implements RequestStreamHandler {
private static final SpringBootLambdaContainerHandler<AwsProxyRequest, AwsProxyResponse> handler;
static {
try {
handler = new SpringBootProxyHandlerBuilder<AwsProxyRequest>()
.defaultProxy()
.asyncInit()
.springBootApplication(StarbucksApiApplication.class)
.buildAndInitialize();
} catch (ContainerInitializationException e) {
// if we fail here, we re-throw the exception to force another cold start
e.printStackTrace();
throw new RuntimeException("Could not initialize Spring Boot application", e);
}
}
@Override
public void handleRequest(InputStream inputStream, OutputStream outputStream, Context context)
throws IOException {
handler.proxyStream(inputStream, outputStream, context);
}
}
Serverless Framework
And the final touch, to configure our Serverless Framework deployment by creating serverless.yml file in the project root:
service: starbucks-api
frameworkVersion: '3'
provider:
name: aws
runtime: java11
region: eu-central-1
environment:
DBPW: ${ssm:dbpw}
package:
artifact: target/starbucks-api-0.0.1-SNAPSHOT.jar
functions:
api:
handler: com.starbucks.api.lambda.StreamLambdaHandler::handleRequest
timeout: 15
memorySize: 2048
events:
- http:
path: /{proxy+}
method: any
Notice the DBPW environment variable? I used AWS Systems Manager Parameter Store to securely store the database password. You should set the DBPW environment variable locally when building the project, if you have any tests that load the Spring’s Context. Feel free to experiment with the memorySize and timeout values.
Finally, build it and deploy it with:
./mvnw clean package -P shaded-jar
serverless deploy
Maven creates the shaded jar and then the Serverless Framework deploys it to AWS Lambda.
The first invocation takes a whopping 11 seconds, even though I’ve put 2 gigs of memory for the Lambda. Cold start seems pretty bad. I haven’t been able to get a response in less than 10 seconds. Warm invocations run in under 100ms on average.
SnapStart to the rescue
Let’s try to optimize this immediately by enabling SnapStart. This is done in serverless.yml by supplying the snapStart: true option to the api function and run serverless deploy.
What we can immediately notice is that the deployment takes about 2 minutes longer. That is because Lambda creates a snapshot of the function and saves it for future invocations. If we test it again, the improvements are huge — cold start time is between 1 and 1.5 seconds. Note that this is observed only on the function level, end-to-end latency is still above 2 seconds for the cold-start invocation. For some reason, API Gateway adds some more latency than usual.
A closer look at duration and pricing
To dive a bit deeper let’s take a look at CloudWatch logs for one particular invocation:
REPORT RequestId: c88a0706-70fa-455b-be3a-1138f981b7e7 Duration: 1124.43 ms Billed Duration: 1423 ms Memory Size: 2048 MB Max Memory Used: 206 MB Restore Duration: 392.10 ms Billed Restore Duration: 298 ms
There are a few important numbers here, and the first one is obviously Duration. That is how long it took to execute the function. Billed Duration is also familiar, but as you can see it is slightly higher than the actual duration. How come? To answer that, we have to look at the two newly added fields — Restore Duration and Billed Restore Duration. The first one is how much it took for Lambda to restore the snapshot and the second one is how much of that time we are charged for. Why are we charged less?
“Restore Duration includes the time it takes for Lambda to restore a snapshot, load the runtime (JVM) and run any afterRestore hooks. You are not billed for the time it takes to restore the snapshot. However, the time it takes for the runtime (JVM) to load, execute any afterRestore hook, and signal readiness to serve invocations is counted towards the billed Lambda function duration.”
Further optimization: Runtime hooks and priming
Turning SnapStart on improved the cold start significantly, we can safely say that for a lot of use cases with some real production load this would be good enough. But ever since it was introduced, there’s been talk about Priming. Runtime hooks allow you to execute some code just before the snapshot is taken, as well as right after the snapshot is restored by Lambda. I encourage you to read a more detailed explanation about it on AWS blog.
In this case, priming comes down to trying to make dummy calls to your code, so it gets compiled and saved with the snapshot, with the goal to speed up the next cold start even more. I tried a few things, and I’ve got mixed results.
Database connections
The first thing I did was just made a request from the beforeCheckpoint hook to one of the endpoints that fetches some data from the database. After deploying to AWS and testing, my cold-start invocation just timed out. I quickly realized that the socket timeout configuration on MongoDB is set to infinity by default, and because the connection to MongoDB was established in the snapshot process, my function was just hanging until the timeout. I changed the socketTimeoutMS setting to something like 500ms and that seemed to work, as the application quickly “realized” that it needs to create a fresh connection to the database. However, it seems that it did add these 500ms to the cold start time, beating the purpose of priming in the first place.
Regardless, default config values probably shouldn’t be used in most production cases anyway.
Priming with dummy calls instead
Not wanting to mess with database connections, I decided to create a dummy request and return a response even before the code tries to fetch something from Mongo. I immediately didn’t like this, as it requires some caveats in parts of the application code. However, after first tests it did seem to reduce the cold start by a few hundred milliseconds.
Let’s take a quick look at the results of testing the same API with and without priming. The load was 1000 requests with the concurrency of 10.
Percentage of the requests served within a certain time (ms) — no priming:
+------------+----------+
| percentage | time(ms) |
+------------+----------+
| 50% | 168 |
| 98% | 378 |
| 99% | 1317 |
| 100% | 2341 |
+------------+----------+
Percentage of the requests served within a certain time (ms) — with priming:
+------------+----------+
| percentage | time(ms) |
+------------+----------+
| 50% | 155 |
| 98% | 497 |
| 99% | 1050 |
| 100% | 1799 |
+------------+----------+
Conclusion
This post showed how easy it can be to build a MongoDB backed Spring Boot Mono-Lambda API, with the benefits of effortless deployment to the cloud with Serverless Framework. While the example is far from being production grade, I think it’s still an interesting experiment. There’s a lot of room to further explore this setup, for example:
- Try MongoDB Atlas Serverless.
- Ramp up security by using VPC peering and Security Groups.
- Configure the Tweak MongoDB connection for future potential production use.
- Test the behavior with slightly larger API.
Learn more
On top of all the links throughout the post, I highly recommend checking out the following as well. These offer additional perspectives and dive deeper into the topic:
Thanks for reading and feel free to reach out to discuss any of the related topics!