Change streams are a feature of Amazon DocumentDB that provides a time-ordered sequence of data change events that occur within a DocumentDB cluster. Change streams can be enabled for an individual collection and can be configured to provide the complete document rather than only the change that occurred. Change streams can be integrated natively with a Lambda function, which gives us wide array of possibilities.
In this tutorial, we will demonstrate step by step how to synchronize real-time data changes from a DocumentDB cluster to an OpenSearch domain using change streams and a Lambda function.
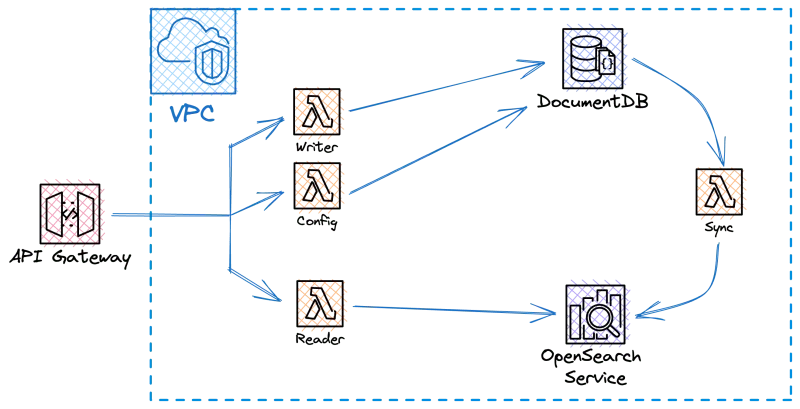
At the end of the tutorial, we will have an infrastructure as shown in the image above. We will create a VPC, DocumentDB cluster, OpenSearch domain, API gateway, and four Lambda functions. Three functions will be exposed via the API gateway: one for writing data, one for reading data, and one for configuring the DocumentDB collection. The fourth function, which is the most important one, will be connected to the change stream and perform data synchronization. Both the functions and the infrastructure will be written in TypeScript and deployed using CDK. The repository containing the entire code can be found here. Let’s get started!
VPC setup
We create a VPC using CDK’s construct. This one-liner creates a VPC with a private and a public subnet and sets up network routing.

Next, we create three security groups: one for Lambda functions, one for the DocumentDB cluster, and one for the OpenSearch domain. As the Lambda functions will perform CRUD operations on data stored in DocumentDB and OpenSearch, we add ingress rules to the DocumentDB and OpenSearch security groups, authorizing access from the Lambda security group. Additionally, we include a self-referencing ingress rule in the DocumentDB security group, which will be explained later on.
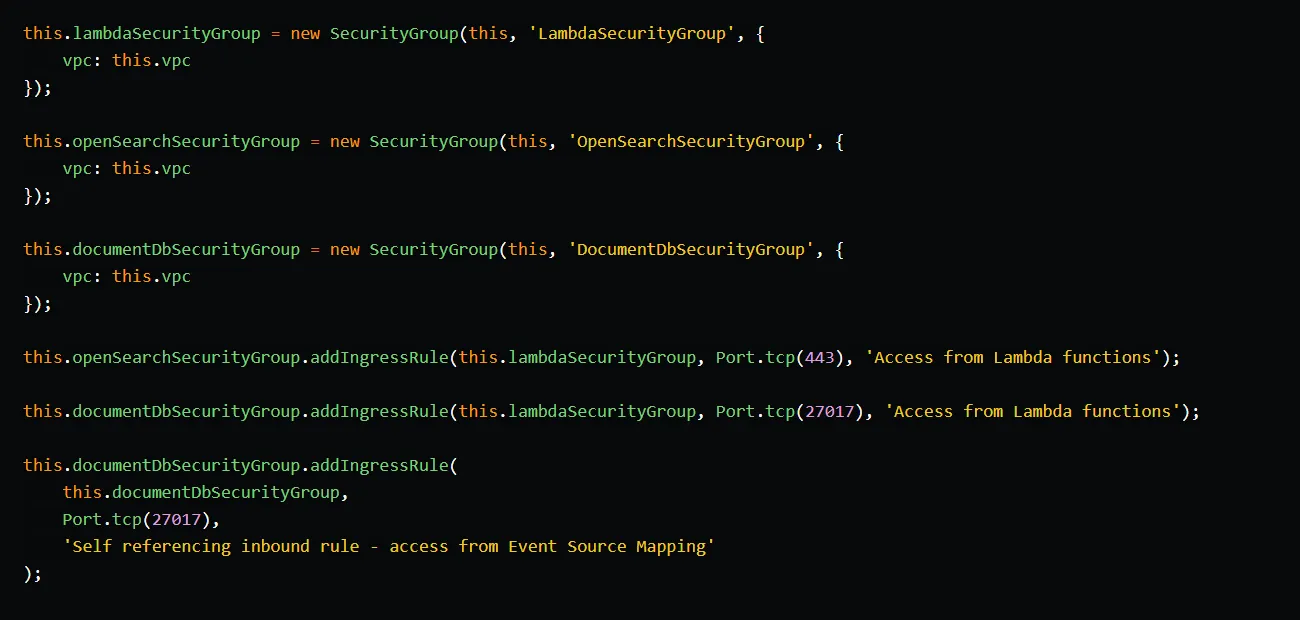
DocumentDB setup
We create a DocumentDB cluster using CDK’s DatabaseCluster construct. The engineVersion is set to 4.0.0 since this is the only version of DocumentDB that supports change streams. The DatabaseCluster creates a master user secret for us and stores it in Secrets Manager under a name defined in masterUser.secretName. We set the vpc and securityGroup properties to the previously created VPC and the DocumentDB security group. To launch the cluster in a private subnet, we set vpcSubnets.subnetType to SubnetType.PRIVATE_WITH_EGRESS. The DatabaseCluster will automatically select private subnets that have only outbound internet access. We also set the removalPolicy to RemovalPolicy.DESTROY to ensure the cluster is deleted when the stack is deleted, avoiding any unexpected costs.
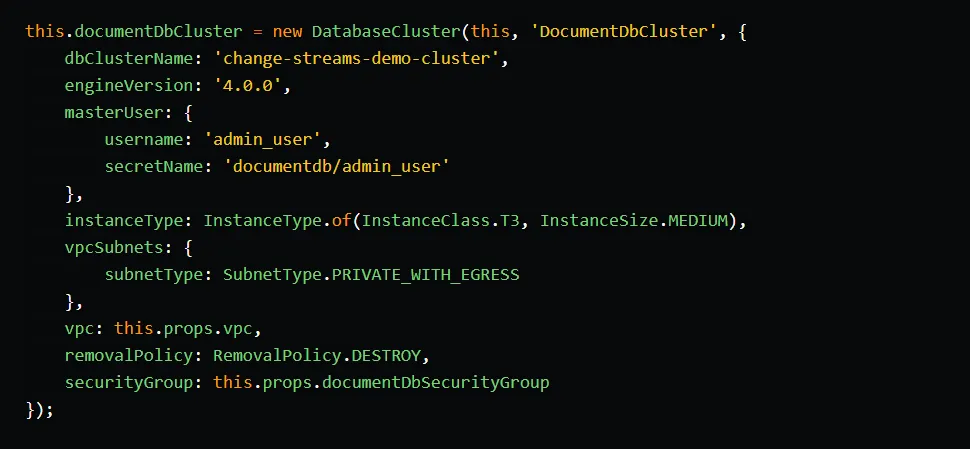
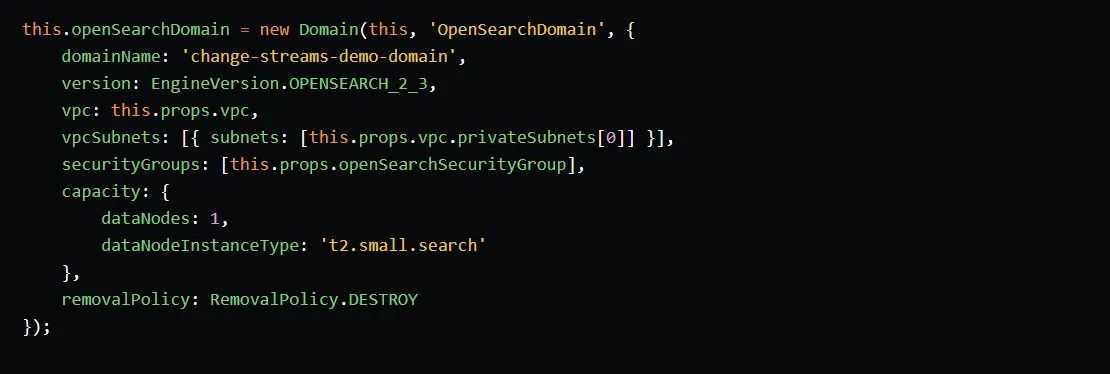
OpenSearch setup
To set up the OpenSearch domain, we utilize CDK’s Domain construct. The properties vpc, securityGroups, and removalPolicy are set in the same manner as for the DocumentDB cluster. For the vpcSubnets property, we cannot use automatic subnet selection as we did in the DocumentDB setup. Instead, it is necessary to explicitly define exactly one private subnet since we only have one OpenSearch node.
For the simplicity of this tutorial, we rely on IAM to authorize access to the OpenSearch domain.
The Domain construct does not create a resource-based IAM policy on the domain, known as the domain access policy. This allows us to authorize access using identity-based policies, such as an IAM role for the Lambda function, without conflicting with the domain access policy. If you wish to explore OpenSearch security in more detail, check out the official documentation available here.
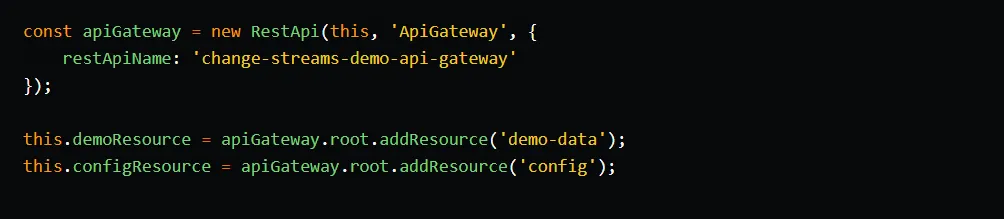
Lambda functions setup
Before we create the Lambda functions, we need to create an API Gateway that will be used to invoke the functions. Similar to other resources, we create the API Gateway using the RestApi construct. We also attach two resources, demo-data and config, to the API Gateway. Later on, we will attach a POST method to the demo-data resource for writing data to DocumentDB, as well as a GET method for reading data from OpenSearch. Additionally, we will attach a POST method to the config resource, which will be used to configure change streams on the DocumentDB collection.
Writing data to the DocumentDB cluster
To be able to write to the DocumentDB cluster, the writer Lambda function requires access to the cluster’s master secret. So, we create an IAM role for our writer function that contains all the necessary permissions. In the inlinePolicies property, we add a new policy that grants access to the cluster’s secret through the secretsmanager:GetSecretValue action. We also include the managed policy AWSLambdaVPCAccessExecutionRole, which provides all the permissions required for running a Lambda function in a VPC and writing logs to CloudWatch.
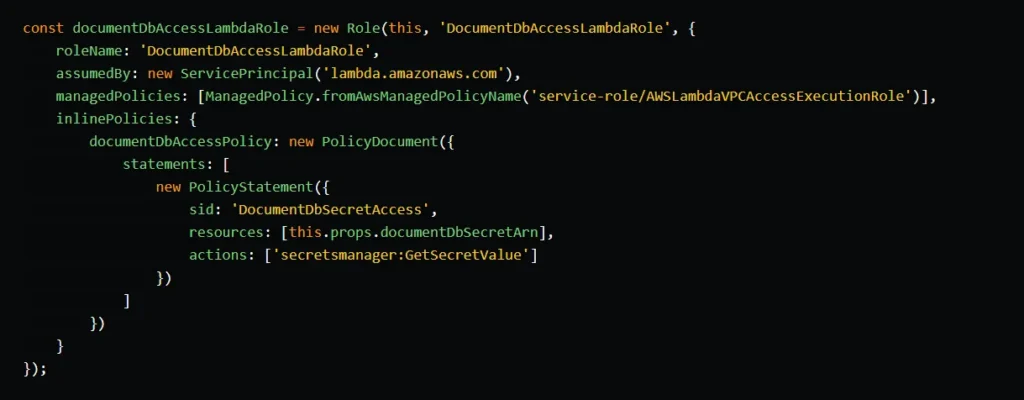
To create the Lambda function, we utilize the NodejsFunction construct. This construct simplifies the process of creating Lambda functions by automatically transpiling and bundling TypeScript or JavaScript code. Under the hood, it utilizes esbuild.
We assign the previously created VPC and security group to the Lambda function using the vpc and securityGroups properties. We configure two environment variables: DOCUMENT_DB_SECRET and DOCUMENT_DB_ENDPOINT. These variables store the ARN of the cluster’s master secret and the endpoint of the cluster, respectively. The Lambda function will utilize these values to establish a connection with the DocumentDB cluster.
By default, the DocumentDB cluster uses TLS (Transport Layer Security). To establish a connection with the cluster, we need to verify its certificate using the AWS-provided Certificate Authority (CA) certificate. The file global-bundle.pem contains the AWS CA certificate. To make it available to the Lambda function during runtime, we use the afterBundling command hook, which copies global-bundle.pem to the Lambda deployment package.
Finally, we attach the Lambda function to the API Gateway as a POST method of the demo-data resource.
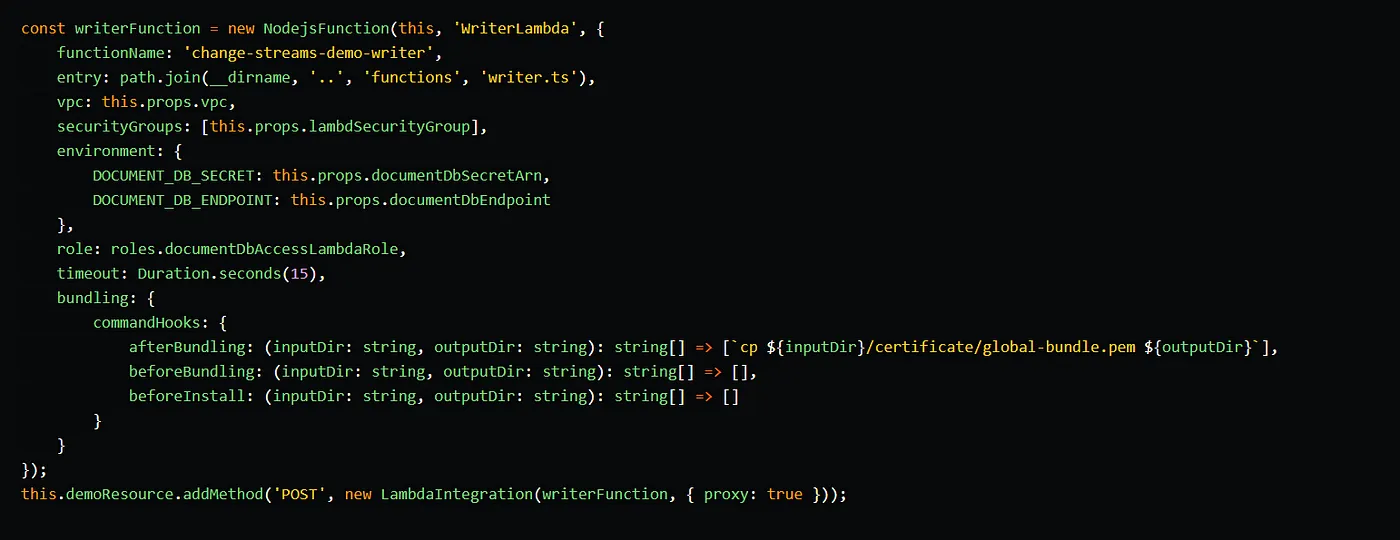
To connect to the DocumentDB cluster, we utilize the mongodb package. Within the createMongoClient() function, we first retrieve the master secret from Secrets Manager. Then we use this secret, along with the previously bundled CA certificate, to establish a connection with the cluster.
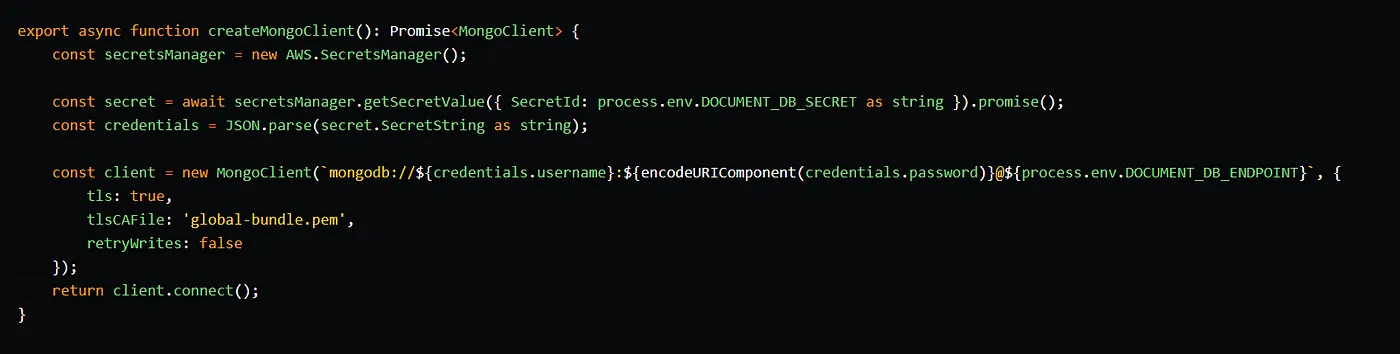
In the handler function, we simply instantiate a MongoClient instance and write the requests’ body to the demo-collection.
Enabling change streams
To utilize change streams, we need to enable them either for the entire DocumentDB database or for the specified collection. Since our DocumentDB cluster is deployed in a private subnet of the VPC, direct access to it is not possible. To overcome this limitation, we create a Lambda function responsible for configuring change streams on the demo collection. This Lambda function is deployed within the VPC and exposed through API Gateway, enabling invocation from outside the VPC.
In a real-world scenario, these configuration tasks would typically be performed either through a script during deployment, such as a CodeBuild job, or manually on the cluster if direct access is available (e.g., via a bastion host or VPN connection). For the purpose of this demo, setting up a Lambda function proves to be the simplest solution.
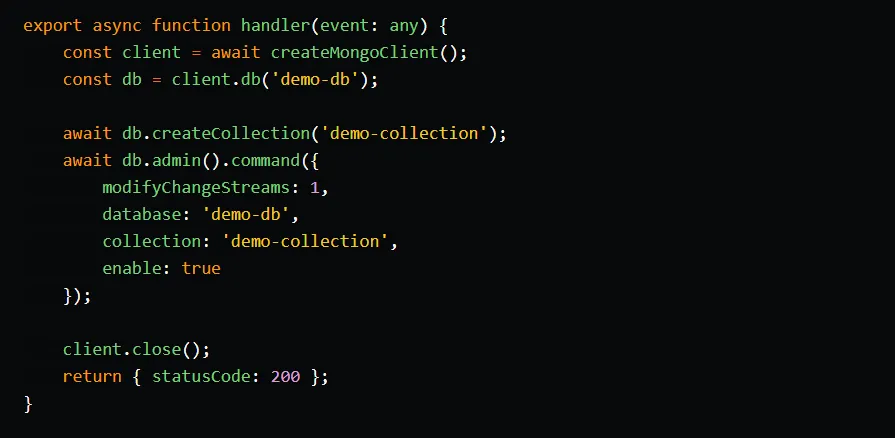
The setup for the configuration Lambda function follows the same steps as the writer function, so we can skip directly to the handler code. In the code, we create the demo-collection collection and execute an admin command to enable change streams on it.
Event Source Mapping setup
An Event Source Mapping (ESM) is a Lambda resource that reads from an event source and triggers a Lambda function. In this case, we use an ESM to read change streams from the DocumentDB cluster and invoke the sync Lambda function. The ESM will handle the connection to the DocumentDB cluster, read the change stream events, group them into batches, and invoke the sync function. In the sync function, we will simply write the entire document to the OpenSearch domain.
To perform its tasks successfully, ESM requires the appropriate permissions both at the networking level and the IAM level. The ESM will “inherit” the security group of the DocumentDB cluster and utilize it when establishing a connection to the cluster. This is precisely why we included a self-referencing inbound rule in the security group of the DocumentDB cluster during the VPC setup. This rule allows the ESM to access the cluster successfully.
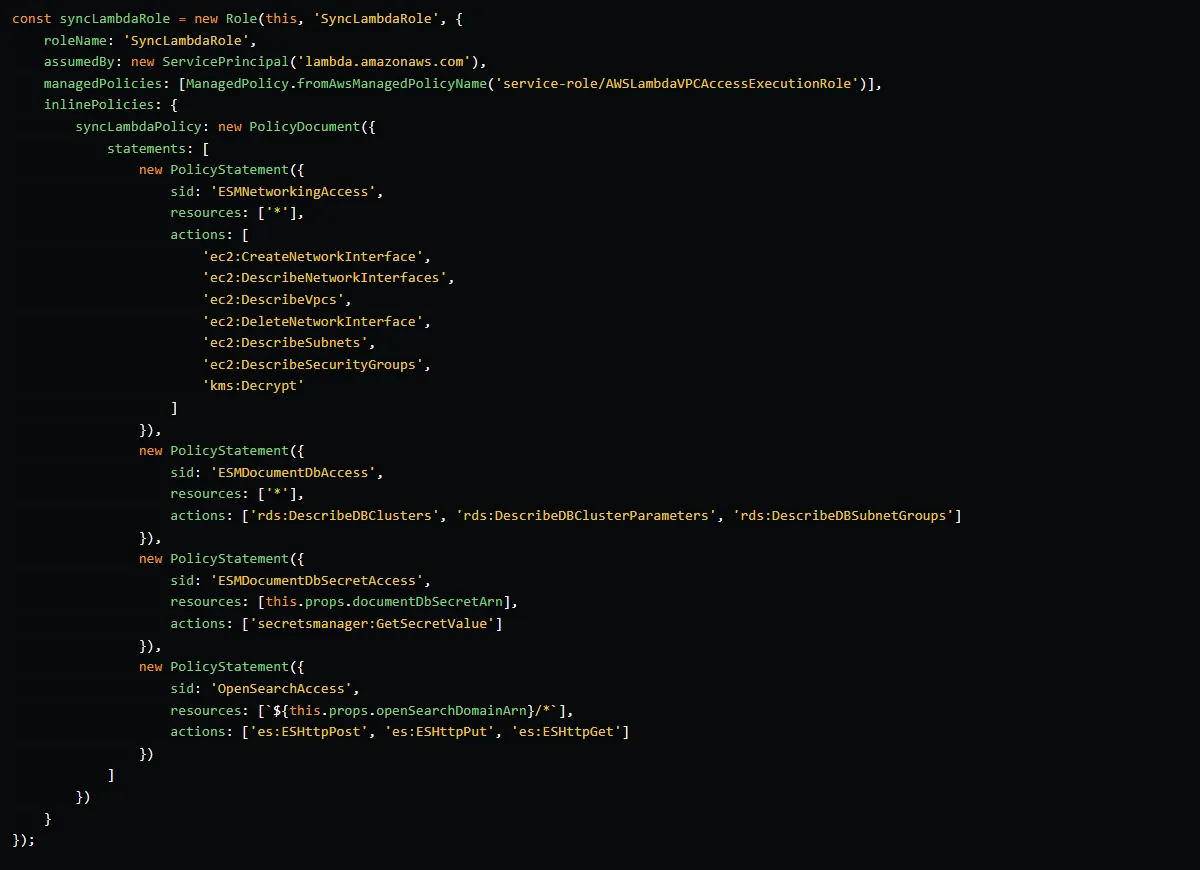
An ESM relies on the permissions granted by the function’s execution role to read and manage items within the event source. Therefore, in the IAM role of the sync function, we include three statements (ESMNetworkingAccess, ESMDocumentDbAccess, ESMDocumentDbSecretAccess) that grant the necessary permissions required by the ESM. The ESMNetworkingAccess statement provides networking permissions, the ESMDocumentDbAccess statement grants DocumentDB management permissions, and the ESMDocumentDbSecretAccess statement allows the ESM to read the master secret of the cluster. We also include an OpenSearchAccess statement, which is utilized by the sync Lambda function itself. The actions es:ESHttpPost, es:ESHttpPut, and es:ESHttpGet within this statement grant the ability to read and write data to the domain or index defined in the resources field.
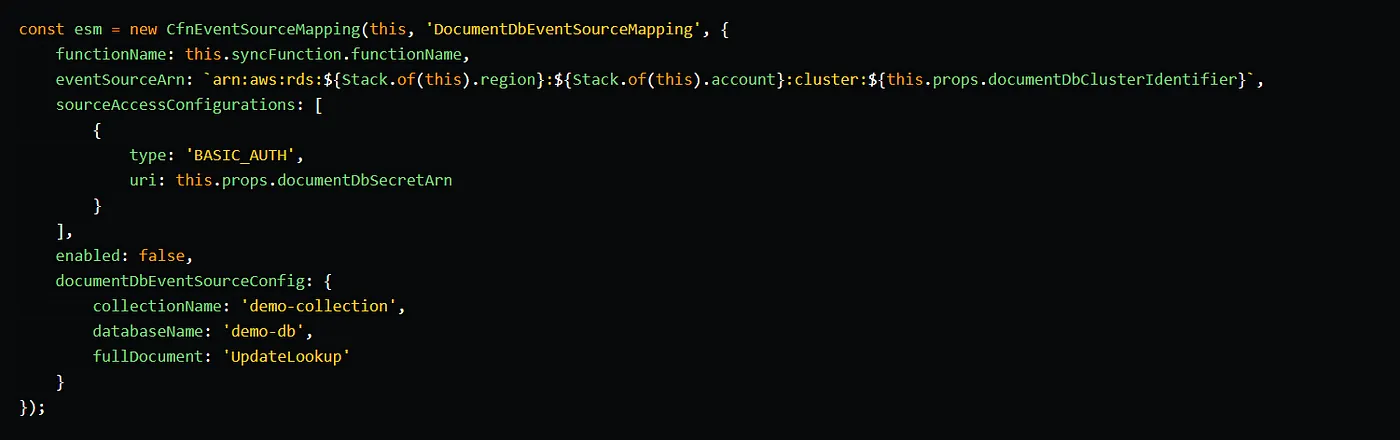
The sync function is defined in the same way as the writer and config functions, using the NodejsFunction construct. So, we can continue to the ESM definition. In the ESM definition, we specify the sync function in the functionName property, the DocumentDB cluster in the eventSourceArn property, and the cluster’s master secret in the sourceAccessConfigurations property.
Within the documentDbEventSourceConfig, we define the database and collection from which we want to read change streams. By specifying the value UpdateLookup in the fullDocument property, we indicate that we want to receive the entire document in the change stream event, rather than just the delta of the change.
We initially set the enabled property to false for the ESM. We will enable ESM later on, once we have set up change streams on the demo collection by invoking the config endpoint. If we were to enable ESM immediately, since it is created before invoking the config method, it would detect that change streams are not enabled, and we would need to restart it.
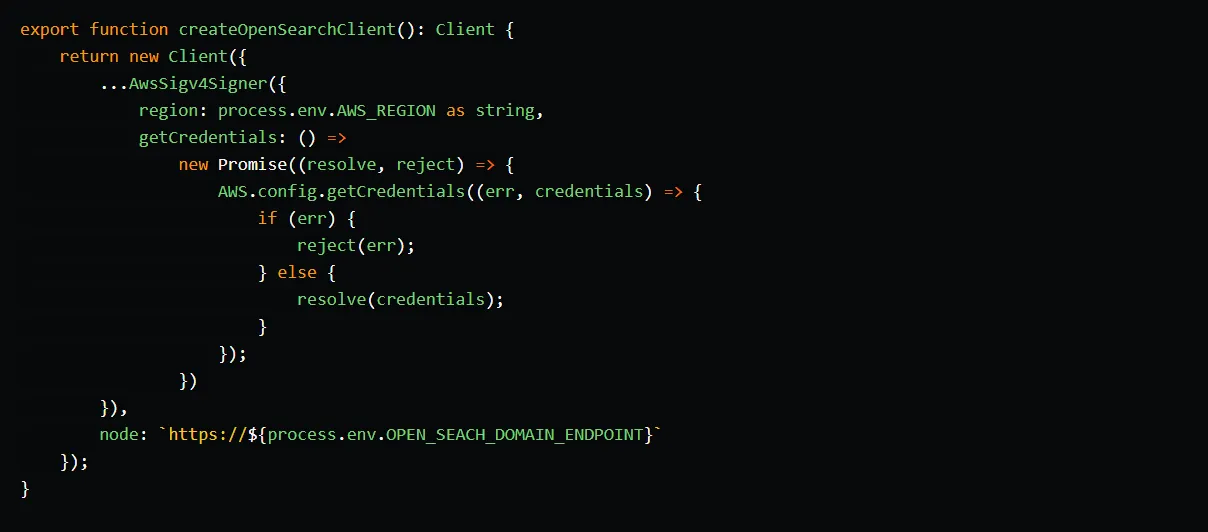
To establish a connection with the OpenSearch domain, we use the Client class from the @opensearch-project/opensearch package. The Client class relies on the AwsSigv4Signer to obtain the credentials of the sync Lambda function and sign requests using the AWS SigV4 algorithm. This signing process is necessary because the OpenSearch domain uses IAM for authentication and authorization.
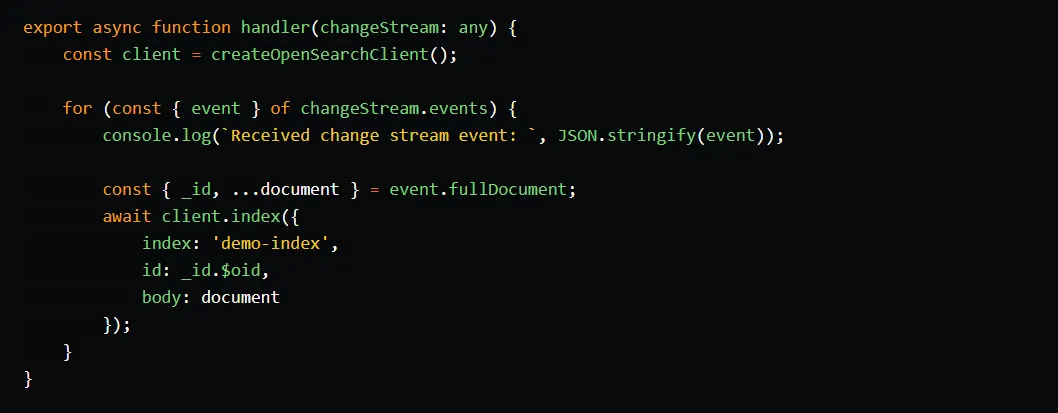
In the sync function code, we simply instantiate an OpenSearch client, iterate through the change stream events, and write them to the demo-index index.
Reading data from the OpenSearch domain
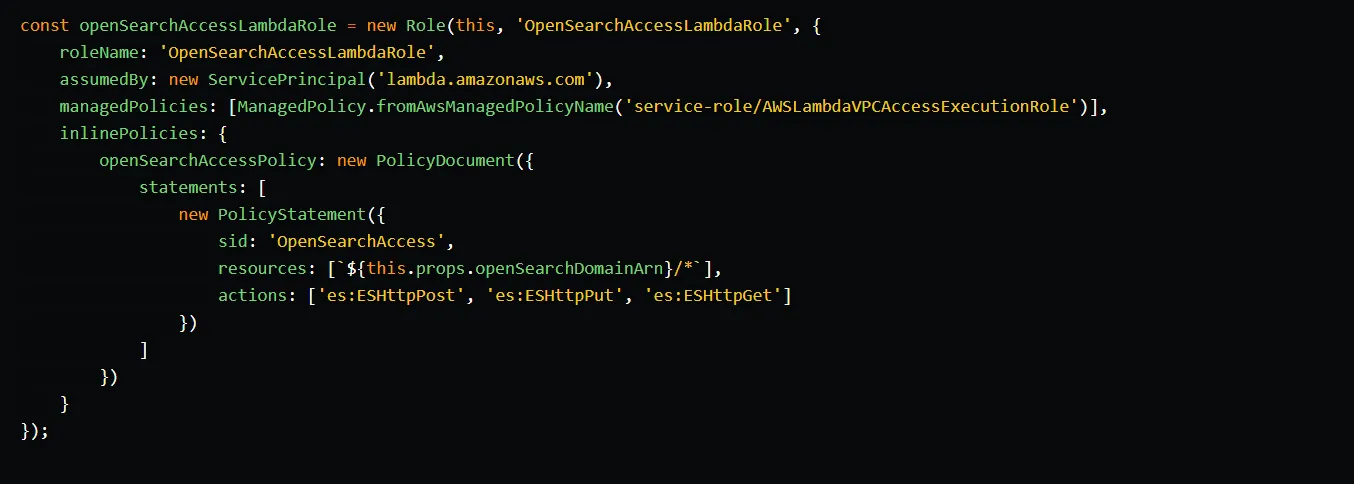
To retrieve data from the OpenSearch domain, we create a reader Lambda function and attach it to the API Gateway. The reader function requires the same OpenSearch permissions as the sync function to access the domain. We create an IAM role specifically for the reader function and, similar to the other functions, we include the managed policy AWSLambdaVPCAccessExecutionRole.
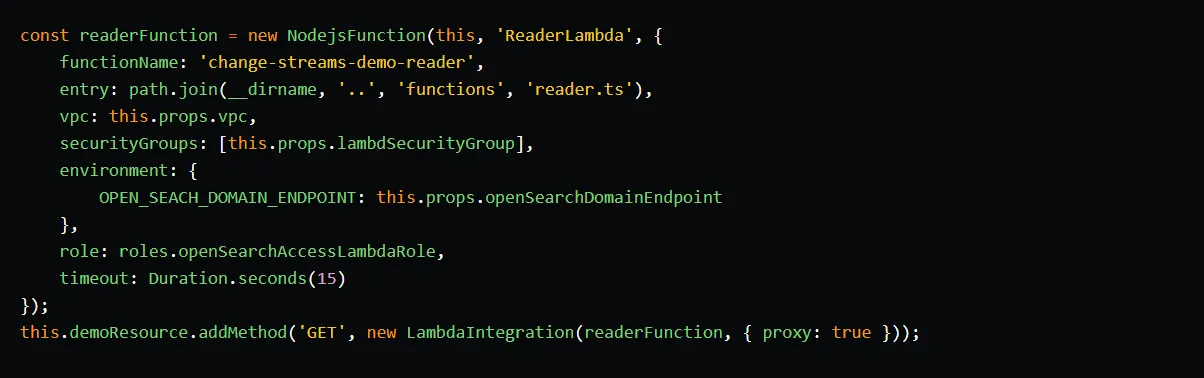
We create the reader function using the NodejsFunction construct. In the function’s environment, we set the OPEN_SEARCH_DOMAIN_ENDPOINT variable and we attach the function to the GET method of the demo-data resource.
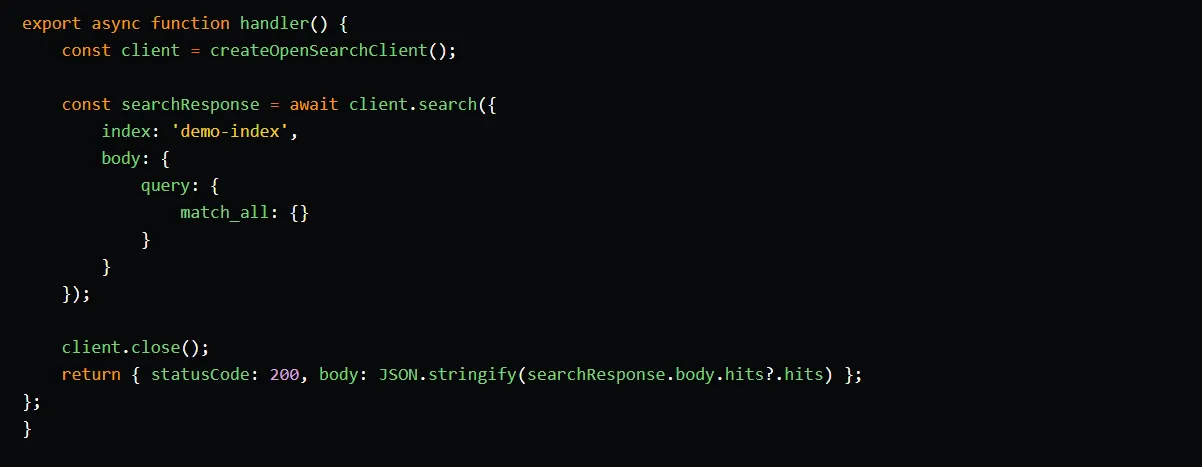
In the function’s code, we instantiate the OpenSearch client, query the demo index, and retrieve the data. We include the retrieved data in the body of the function’s response, returning it to the caller.
Deploying and testing the synchronization
Before deploying the solution, it is necessary to enable the service-linked role for the OpenSearch service. When performing operations through the AWS Console, this service-linked role is automatically created when required. Therefore, if you have previously set up the OpenSearch domain using the AWS Console, you should already have the service-linked role created. However, if it is not available, you can create it using the AWS CLI command shown below.

The entire CDK code is organized into four stacks:
- change-streams-demo-vpc-stack: Contains VPC definition and security groups.
- change-streams-demo-documentdb-stack: Defines the DocumentDB cluster.
- change-streams-demo-opensearch-stack: Sets up the OpenSearch domain.
- change-streams-demo-lambda-stack: Creates the API Gateway and Lambda functions.
To deploy the entire solution, you can run the npm command shown below. By default, the command will use the account, region, and credentials from your default AWS profile.

After the deployment is completed, you will need to retrieve the URL of the API Gateway. Once you have the URL, the next step is to invoke the config endpoint. This will create the demo collection and enable change streams.

After invoking the config endpoint, you need to enable the ESM. You can do this by executing the command below. The ID of the ESM can be found as the value of the esm-id output of the change-streams-demo-lambda-stack stack. Alternatively, you can enable the ESM by opening the sync Lambda function in the AWS console, selecting and enabling ESM from the list of triggers of the function.

Now you can start adding data to the DocumentDB cluster by invoking the POST method of the demo-data endpoint.
Once the data is added, it will be synchronized to the OpenSearch domain. To retrieve the synchronized data, you can invoke the GET method of the demo-data endpoint.

The response from invoking the GET method of the demo-data endpoint should contain the same data that was added through the POST method. You can monitor the execution and logs of the Lambda function using the CloudWatch service.
After testing the synchronization, you can delete the resources by invoking the command below. Stateful resources, such as the DocumentDB cluster and OpenSearch domain, are configured with the RemovalPolicy.DESTROY and will be deleted along with the stacks.

All created resources are tagged with the Application tag, which has the value change-streams-demo. Once the destroy command completes execution, you can double-check if all resources have been deleted by using the Tag Editor of the AWS Resource Groups service. The Tag Editor allows you to search for resources based on their tags. Any remaining resources can be deleted manually.
Conclusion
In this post, I have demonstrated how to achieve real-time data synchronization from a DocumentDB cluster to an OpenSearch domain using change streams and a Lambda function. The majority of the heavy lifting is handled by AWS on our behalf. For instance, the Event Source Mapping performs all the complex tasks, such as polling for changes and grouping them into batches, while we simply integrate our Lambda function into the flow.
The architecture example presented here can be used to enhance the search performance of an existing DocumentDB cluster by replicating its data into a search-optimized OpenSearch domain. This is just one example of the numerous possibilities that change streams offer. Since they are easily integrated with Lambda functions, we have the flexibility to use them in any way we desire. For instance, we could react to events within the DocumentDB cluster and trigger a Step Function or send notifications to users and more.
I hope you found this post useful and interesting. If you have any questions regarding the implementation or encounter any deployment issues, feel free to leave a comment below. I’ll make sure to respond as promptly as possible.